
mysql 에서 JdbcCursorReader 를 사용했는데 뭔가 이상한 부분 확인
- 분명히 fetch size 2 로 지정했는데, reader 의 doRead() 를 디버깅해볼시 전체 데이터를 들고 있음.
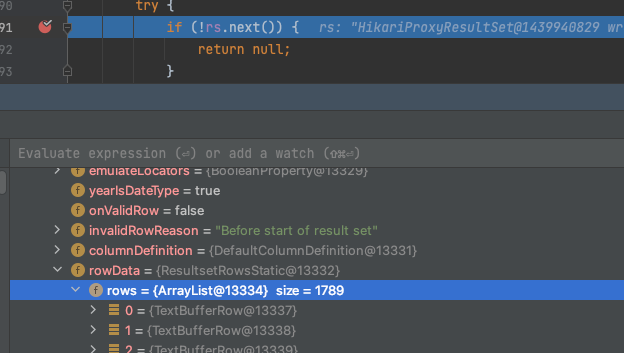
- 그리고 결과 값이
ResultSetRowsStatic임. cursor 를 똑바로 썼으면ResultSetRowsCursor임1 2 3 4 5 6 7 8 9 10 11 12 13
@Bean public JdbcCursorItemReader<SomeThing> reader(DataSource dataSource) throws Exception { JdbcCursorItemReader<SomeThing> reader = new JdbcCursorItemReaderBuilder<SomeThing>() .name("cursorTestReader") .dataSource(dataSource) .fetchSize(2) .verifyCursorPosition(false) .rowMapper((rs, rowNum) -> something) .sql("SELECT * FROM table") .build(); reader.afterPropertiesSet(); return reader; }
![img]()
- 본래 JdbcCursorItemReader 는 fetchSize 만큼만 데이터를 들고,
- 다 소비하면 db 에 다음 데이터를 요청해 적은양의 메모리로 무한한 대용량을 처리 할 수 있는 Reader 임.
- 물론 큰데이터를 저용량으로 처리하면, 시간이 오래걸려서 그만큼 Connection + Transaction 을 길게 가져가게 되는 문제가 있음.
한번에 데이터를 메모리에 다 올리게되면
- 일단 저렇게 다 올라가면, 메모리 용량 이슈를 피할 수 없고, CursorReader 를 쓰는 이점을 모두 잃게됨
- 왜 Why? 동작을 하지 않는 것일까..?
CursorReader 의 장점과 사용처
- 적은 메모리에 Cursor 를 움직이며 ‘조금씩’ 데이터를 가져옴.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
//ResultsetRowsCursor.java @Override public Row next(){ if(this.fetchedRows==null&&this.currentPositionInEntireResult!=BEFORE_START_OF_ROWS){ throw ExceptionFactory.createException(Messages.getString("ResultSet.Operation_not_allowed_after_ResultSet_closed_144"), this.protocol.getExceptionInterceptor()); } if(!hasNext()){ return null; } this.currentPositionInEntireResult++; this.currentPositionInFetchedRows++; // Catch the forced scroll-passed-end if(this.fetchedRows!=null&&this.fetchedRows.size()==0){ return null; } if((this.fetchedRows==null)||(this.currentPositionInFetchedRows>(this.fetchedRows.size()-1))){ fetchMoreRows(); this.currentPositionInFetchedRows=0; } Row row=this.fetchedRows.get(this.currentPositionInFetchedRows); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
private void fetchMoreRows() { if (this.lastRowFetched) { this.fetchedRows = new ArrayList<>(0); return; } this.protocol.sendCommand( this.commandBuilder.buildComStmtFetch(this.protocol.getSharedSendPacket(), this.owner.getOwningStatementServerId(), numRowsToFetch), true, 0); Row row = null; while ((row = this.protocol.read(ResultsetRow.class, this.rowFactory)) != null) { this.fetchedRows.add(row); } this.currentPositionInFetchedRows = BEFORE_START_OF_ROWS; .... }
- chunk size 가 차면 writer 로 데이터를 넘기지만, 연결을 끊지 않고 커넥션 유지.
- 너무 오래걸리는 처리의 경우 transaction 이 길어짐
- 멀티쓰레드로 하지 못해서 처리가 너무 오래걸리는건 느릴 수 있음.
- 적은 메모리로, 초대용량 처리를 할 수 있음. 커넥션 타임아웃만 길게 잡으면 무한에 가까운 처리 가능.
- 와이어샤크로 볼 시 DB에서 데이터를 가져와야하기 떄문에 네트워크 입출력 횟수가 많을 수 밖에 없음.
mysql 에서 정상적으로 사용하고 싶을 시 옵션을 추가해야함
- mysql-connector-java 드라이버가 깡으로는 cursor fetch 기능을 사용하지 못하게함.
jdbc:mysql://localhost/?useCursorFetch=trueconnection 맺을 때, 이 옵션을 주지 않으면 Cursor의 기능을 쓸 수 없음.- 누락시 그냥 일반 쿼리처럼 한번에 전체 데이터를 가지고 오게됨.
자매품 maria db 에선 어떨까
- maria db 드라이버는 훌륭하게 지원함. 아무 옵션 없이 그냥 바로 사용 가능함.
- maria db 구현체는 StreamingResultSet.java 인데, 개발자가 지정한 fetchSize 사이즈만큼 응답을 넘겨줍니다.
결론
- 장비가 보통 빵빵한 회사에선 쓸일이 많이 없다.
- 거의 무한한 데이터를 처리할 떄 장애 없이 효율적일 것이다.
참고 블로그
- https://heowc.dev/2019/02/09/using-mysql-jdbc-to-handle-large-table-1/
- https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-reference-implementation-notes.html